- Hvordan lærer jeg BeautifulSoup?
- Hvordan bruker du vakker suppe i Python?
- Hvordan bruker du vakker suppe i Python til nettskraping?
- Hvordan skraper du med BeautifulSoup?
- Er nettskraping lovlig?
- Er Python gratis?
- Hvorfor brukes BeautifulSoup i Python?
- Er BeautifulSoup raskere enn selen?
- Hva er nettskraping ved hjelp av Python?
- Er skraping av Amazon lovlig?
- Hvordan skraper jeg Amazon-produkter med Python BeautifulSoup?
- Hva er det beste verktøyet for skraping av nettet?
Hvordan lærer jeg BeautifulSoup?
Nybegynnerveiledning for nettskraping i Python ved hjelp av BeautifulSoup
- Lær nettskraping i Python ved hjelp av BeautifulSoup-biblioteket.
- Web Scraping er en nyttig teknikk for å konvertere ustrukturerte data på nettet til strukturerte data.
- BeautifulSoup er et effektivt bibliotek tilgjengelig i Python for å utføre nettskraping annet enn urllib.
Hvordan bruker du vakker suppe i Python?
Først må vi importere alle bibliotekene vi skal bruke. Deretter erklærer du en variabel for url på siden. Bruk deretter Python urllib2 for å få HTML-siden til url erklært. Til slutt kan du analysere siden i BeautifulSoup-format slik at vi kan bruke BeautifulSoup til å jobbe med den.
Hvordan bruker du vakker suppe i Python til nettskraping?
Bruke BeautifulSoup til å analysere HTML-innholdet
- Importer BeautifulSoup-klasseskaperen fra pakken bs4 .
- Parse svar. tekst ved å opprette et BeautifulSoup-objekt, og tilordne dette objektet til html_soup . Html. parser-argumentet indikerer at vi vil utføre parsing ved hjelp av Pythons innebygde HTML-parser.
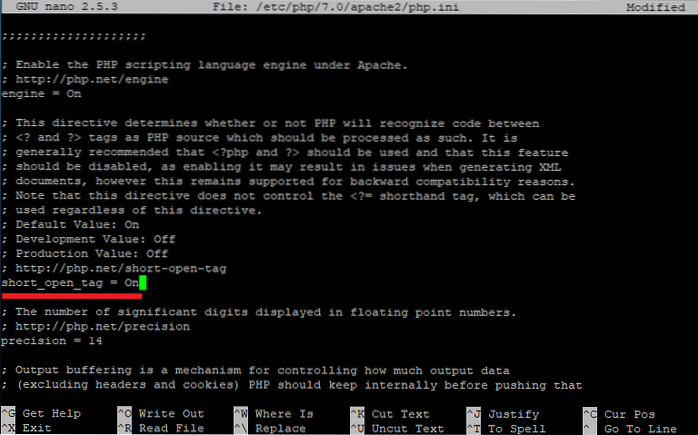
Hvordan skraper du med BeautifulSoup?
La oss prøve å forstå dette kodestykket.
- Først og fremst importerer du forespørselsbiblioteket.
- Spesifiser deretter URL-adressen til websiden du vil skrape.
- Send en HTTP-forespørsel til den angitte URL-en, og lagre svaret fra serveren i et svarobjekt kalt r.
- Nå, som utskrift r. innhold for å få det rå HTML-innholdet på websiden.
Er nettskraping lovlig?
Så er det lovlig eller ulovlig? Nettskraping og gjennomgang er ikke ulovlig av seg selv. Tross alt kan du skrape eller gjennomsøke ditt eget nettsted uten problemer. ... Store selskaper bruker nettskraper for egen gevinst, men vil heller ikke at andre skal bruke roboter mot dem.
Er Python gratis?
Python er et gratis programmeringsspråk med åpen kildekode som er tilgjengelig for alle å bruke. Det har også et stort og voksende økosystem med en rekke åpen kildekode-pakker og biblioteker. Hvis du vil laste ned og installere Python på datamaskinen din, kan du gjøre det gratis på python.org.
Hvorfor brukes BeautifulSoup i Python?
Beautiful Soup er et Python-bibliotek for å få data ut av HTML, XML og andre markup-språk. Si at du har funnet noen nettsider som viser data som er relevante for forskningen din, for eksempel dato- eller adresseinformasjon, men som ikke gir noen måte å laste ned dataene direkte.
Er BeautifulSoup raskere enn selen?
Nettskraper som bruker enten Scrapy eller BeautifulSoup, bruker Selenium hvis de trenger data som bare kan være tilgjengelige når Javascript-filer lastes inn. Selen er raskere enn BeautifulSoup, men litt tregere enn Scrapy.
Hva er nettskraping ved hjelp av Python?
Nettskraping er et begrep som brukes for å beskrive bruken av et program eller en algoritme for å trekke ut og behandle store mengder data fra nettet. ... Enten du er datavitenskapsmann, ingeniør eller noen som analyserer store mengder datasett, er muligheten til å skrape data fra nettet en nyttig ferdighet å ha.
Er skraping av Amazon lovlig?
Det er lovlig å skrape Amazonas nettsted med dataene som er tilgjengelige for folket. Dataene som amazon har gjort private og blokkerte alle crawlere, er ikke lovlig å skrape dem og kan være gjenstand for juridiske problemer, og amazon kan til og med saksøke personen eller crawleren som prøver å gjennomgå disse spesifikke dataene.
Hvordan skraper jeg Amazon-produkter med Python BeautifulSoup?
Nærme seg:
- Først skal vi importere de nødvendige bibliotekene våre.
- Så tar vi URL-en som er lagret i tekstfilen vår.
- Vi vil mate URL-adressen til suppeobjektet vårt, som deretter trekker ut relevant informasjon fra den angitte URL-en. basert på element-ID-en gir vi den og lagrer den i CSV-filen.
Hva er det beste verktøyet for skraping av nettet?
Topp 8 verktøy for nettskraping
- ParseHub.
- Skrapete.
- OctoParse.
- Skraper-API.
- Mozenda.
- Webhose.io.
- Content Grabber.
- Vanlig gjennomgang.